关于更正《大数据ETL技术中的数据抽取方法》
原文中第一次对比求出了 CuB 和 CuA 两个补集,第二次拉取真实数据进行二次比对,根据在实际生产环境汇总应用时发现,在第二次比对中拉取原文数据是可以省略的,所以更正了上一篇文章的ETL操作步奏。
进入阅读
Hadoop入门教程(一):Hadoop 是什么 Hadoop 由什么组成
在上一大章节我们讲了大数据仓库的概念,我们了解了数仓的建设思想,接下来我们就开始让我们的思想慢慢变为现实,承载这一切的基础就是 Hadoop 生态圈中的各种大数据组件,慢慢形成我们的大数据仓库和平台。
进入阅读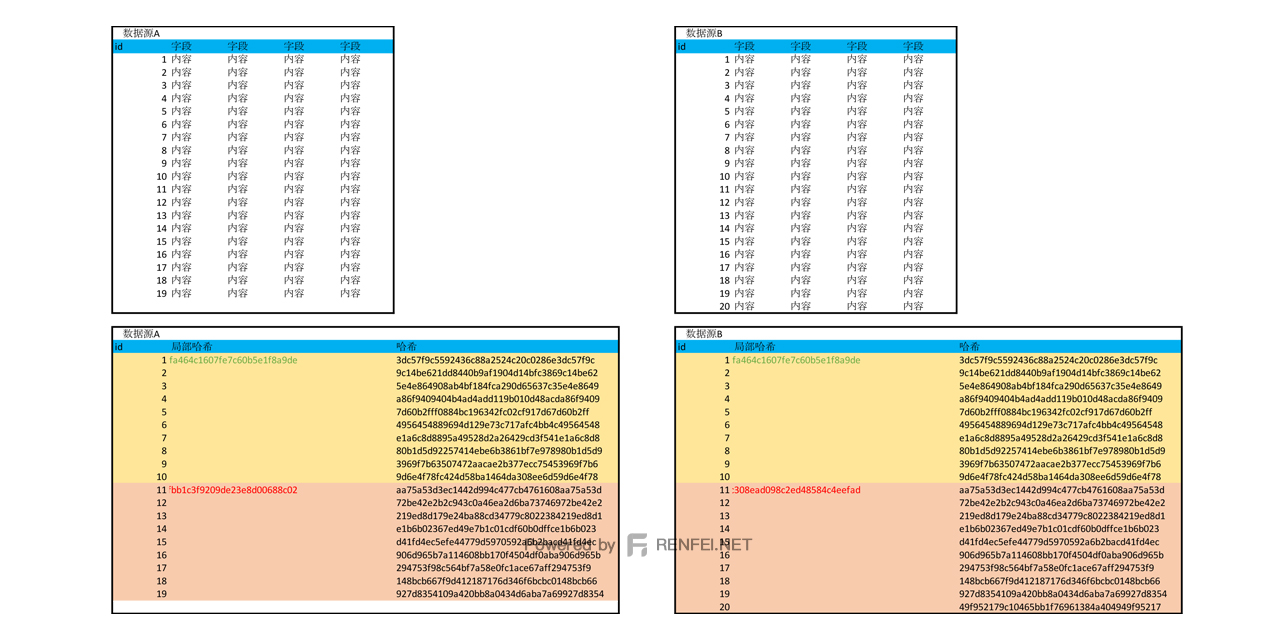
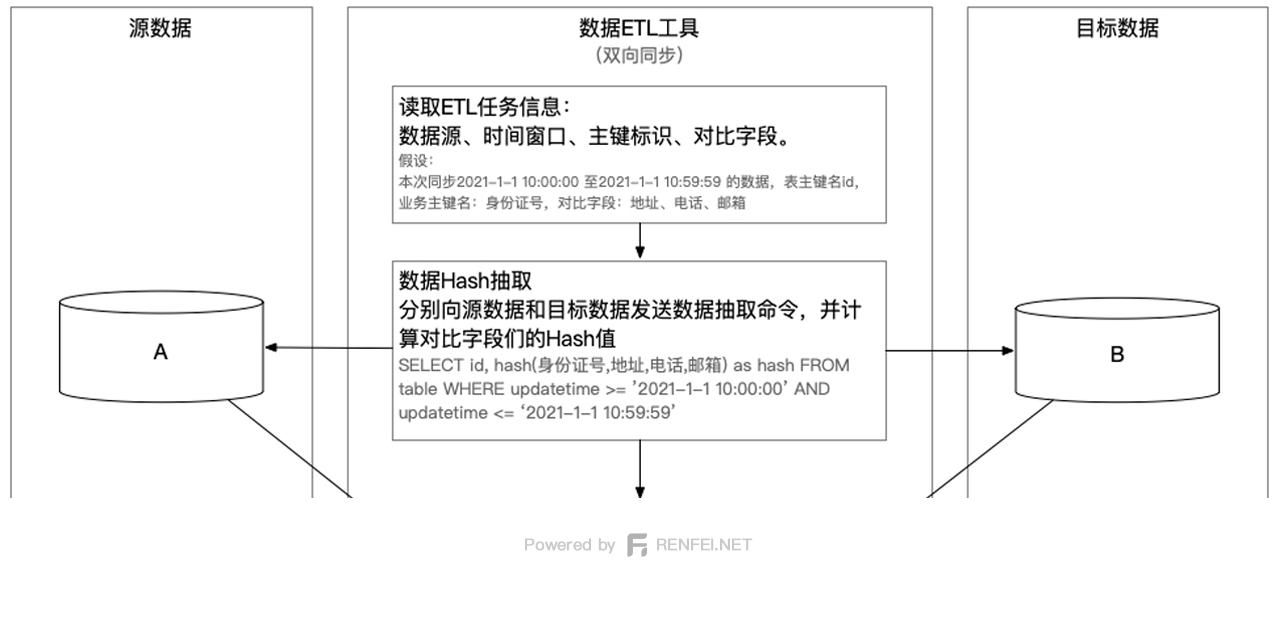
大数据ETL技术中对数据进行局部哈希对比优化对比速度
在上一篇文章中我们通过对每条数据的所有字段进行了哈希摘要,将几十个字段摘要成了一串哈希值,加快的我们的对比速度,但这只是将字段进行了压缩,数据的数量还是没有被压缩,如果有几十亿条数据,我们还是不能快速的找到变化的数据。
进入阅读
数据仓库的概念(四):全量表、增量表、拉链表、流水表、快照表
上一篇文章我们了解了事实表、维度表和星型模型、雪花模型,除了这些在行业中还有一些专业名词需要了解,本篇文章将带你了解大数据行业“黑话”全量表、增量表、拉链表、流水表、快照表都是什么。可能下面的一些内容理解不了,等到搞 hive 的时候就知道了,先了解一下基本的知识。
进入阅读
数据仓库的概念(三):数据模型设计事实表、维度表、星型模型、雪花模型
在上一篇数据仓库分层设计中,我们还提到了各个层除了原始表还进行了一些加工,在加工的时候还提到了事实表、维度表,本文带你粗略的理解一下事实表、维度表,数据模型中的星型模型、雪花模型。
进入阅读
数据仓库的概念(二):数据仓库的分层设计
随着数据随时间流入我们的数据仓库以后,数据的种类和数量将越来越庞大,如果不加以治理和设计,我们查询取用数据时将遇到很大的问题,所以就需要对数据仓库进行设计,让数据分门别类的放到自己应该去的地方,方便我们日后随时调用查取。
进入阅读
数据仓库的概念(一):什么是数据仓库与数据库有什么不同
本文作为开启大数据技术入门级系列教程首篇文章,我们使用的任何大数据组件和工具其实都是在解决数据的问题,而数据就需要通过数据仓库存取,无论你使用什么样的技术架构都离不开数据仓库,所以第一篇文章先了解一下什么是数据仓库,以及数据仓库和数据库有什么区别。
进入阅读
大数据技术入门级系列教程
包括大数据数据仓库的概念、Hadoop入门教程、Zookeeper入门教程、Hive入门教程、Flume入门教程、Kafka入门教程、Hbase入门教程、Sqoop入门教程、Oozie入门教程、azkaban入门教程、Kylin入门教程、CDH入门教程、Impala入门教程、Hue入门教程、ClickHouse入门教程、Kettle入门教程、Ambari入门教程、ELK入门教程、Scala入门教程、Flink入门教程
进入阅读
大数据ETL技术中的数据抽取方法
说到大数据仓库技术,不得不提ETL,ETL一词较常用在数据仓库,但其对象并不限于数据仓库。可以说是非常重要的一个环节,简单介绍一下ETL数据抽取比对的方法。
进入阅读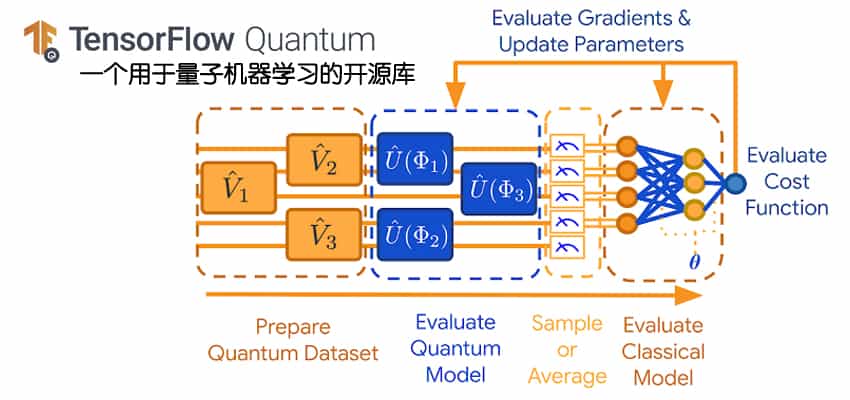
Google 发布 TensorFlow Quantum:用于量子机器学习的开源库
3月9日,Google AI 官方发表博文,正式发布 TensorFlow Quantum(TFQ),这是一个用于快速建立量子机器学习模型原型的开源库。TFQ 提供了必要的工具,可以将量子计算和机器学习研究界聚集在一起,以控制和建模自然或人工量子系统。例如有噪声的中规模量子(Noisy Intermediate Scale Quantum,NISQ)处理器,具有约 50-100 量子位。
进入阅读
Apache NiFi 术语词汇解释
进入阅读
- 前后端分离项目接口数据加密的秘钥交换逻辑(RSA、AES)
- OmniGraffle 激活/破解 密钥/密匙/Key/License
- Redis 未授权访问漏洞分析 cleanfda 脚本复现漏洞挖矿
- CleanMyMac X 破解版 [TNT] 4.6.0
- OmniPlan 激活/破解 密钥/密匙/Key/License
- Parallels Desktop For Mac 16.0.1.48911 破解版 [TNT]
- Parallels Desktop For Mac 15.1.4.47270 破解版 [TNT]
- 人大金仓 KingbaseES V8 R3 安装包、驱动包和 License 下载地址
- Sound Control 破解版 2.4.2
- CleanMyMac X 破解版 [TNT] 4.6.5
- 博客完全迁移上阿里云,我所使用的阿里云架构
- 微软确认Windows 10存在bug 部分电脑升级后被冻结
- 大佬们在说的AQS,到底啥是个AQS(AbstractQueuedSynchronizer)同步队列
- 比特币(BTC)钱包客户端区块链数据同步慢,区块链数据离线下载
- Java中说的CAS(compare and swap)是个啥
- 小心免费主题!那些WordPress主题后门,一招拥有管理员权限
- 强烈谴责[wamae.win]恶意反向代理我站并篡改我站网页
- 讨论下Java中的volatile和JMM(Java Memory Model)Java内存模型
- 新版个人网站 NEILREN4J 上线并开源程序源码
- 我站近期遭受到恶意不友好访问攻击公告