数据仓库的概念(二):数据仓库的分层设计
2021年02月03日 10:43:43 · 本文共 1,423 字阅读时间约 5分钟 · 4,163 次浏览
上一篇我们了解了数据仓库的作用,随着数据随时间流入我们的数据仓库以后,数据的种类和数量将越来越庞大,如果不加以治理和设计,我们查询取用数据时将遇到很大的问题,所以就需要对数据仓库进行设计,让数据分门别类的放到自己应该去的地方,方便我们日后随时调用查取。
任霏注:本文中讲到的数仓分层设计大多源自国内阿里巴巴的《大数据之路》,国外英文文献中搜索不到 DWD/DWS 等描述,而且这个分层设计只是推荐并没有标准答案,有可能并不适合你的行业数据结构,这个思想会有利于构建自己行业的数据结构和模型。
为什么要分层
如果我们不对原始数据进行治理,当数据达到海量的时候,你会发现当你想要一个分析图表的时候,数据查询会非常吃力,可能要关联几百个表,扫描全部几TB的数据,所以我们可以用空间换时间:通过建设多层次的数据模型供用户使用,避免用户直接使用操作原始数据,可以更高效的访问数据。同时可以将复杂的问题分解成单个简单的步奏来完成,比较简单和容易理解。
数仓分层
注意数仓分层并没有标准答案,我这里讲述的是阿里巴巴的解决方案,大部分将数仓分为四层,虽然名称和缩写可能不太一样,请领会里面的思想,不要纠结分层必须是哪些层。
根据阿里的大数据计算服务(MaxCompute,原名ODPS)以及阿里巴巴的《大数据之路》中给出的解决方案,数仓将分为四层:数据层( Operational Data Store, ODS)、明细数据层( Data Warehouse Detail , DWD )、汇总数据层( Data Warehouse Summary, DWS )和 应用数据层(ApplicationDataStore, ADS)。这里引用阿里云对MaxCompute的描述:
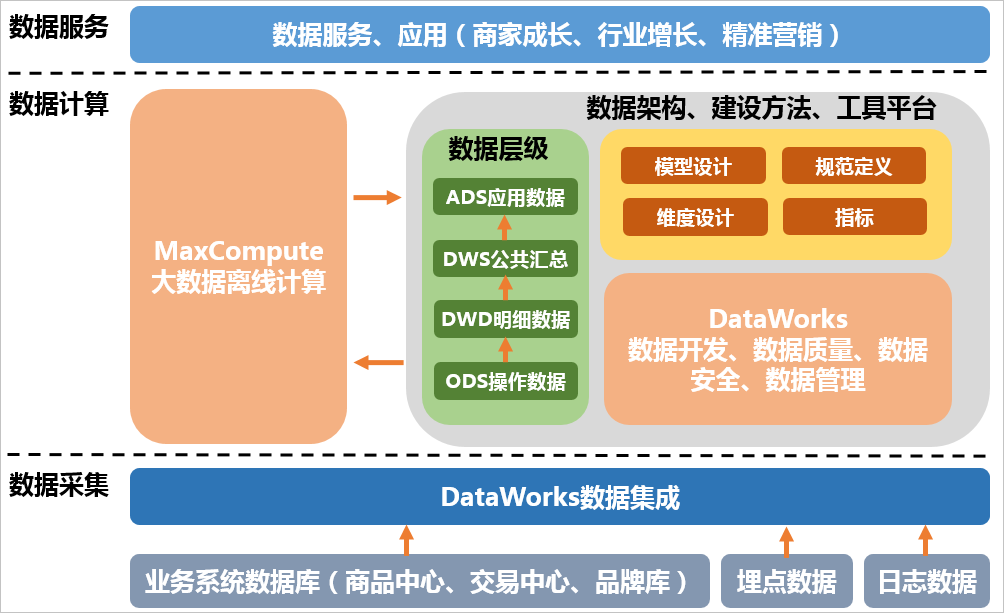
数据层( Operational Data Store, ODS)
ODS 有时候我们也叫它贴源层,因为这里存放的是最原始的数据,我们什么也不改变,就保留原始数据的内容,结构上与源系统保持一致,是数据仓库的数据准备区。
我们从原始系统抽取来的数据就存放在这里,从这里进入我们的大数据平台,在这个区域我们只做查询操作,不要进行修改和删除任何数据!
明细数据层( Data Warehouse Detail , DWD )
DWD 这层和 ODS 层保持一样的数据结构,只不过在从 ODS 里抽取到 DWD 的时候这个过程叫 ETL,后面我们会再讲 ETL,在抽取时对数据进行清洗加工,提供一定的数据质量保证,提供更干净的数据。
同时会进行维度退化,当一个维度没有数据仓库需要的任何数据时,就可以退化维度,将维度退化至事实表中,减少事实表和维表的关联。后面我们再讲维度表和事实表,这里只讲数据仓库分层。
汇总数据层( Data Warehouse Summary, DWS )
这层主要进行轻度汇总,也称为宽表层,有的地方叫数据服务层( Data Warehouse Service, DWS ),不用纠结叫法和缩写翻译,请领会治理思想。
这里表的数量将大幅度下降,大多按照主题进行划分,例如订单、用户等,但这些表的字段比较多,所以也叫宽表,由于上一层 DWD 进行了维度退化,这里的数据可能出现冗余,例如订单ID可能存在于多个事实表中,这是正常的,用于提供后续的业务查询。
然后补充上阿里对这层的描述,读着有点拗口:
以分析的主题对象作为建模驱动,基于上层的应用和产品的指标需求,构建公共粒度的汇总指标事实表,以宽表化手段物理化模型。构建命名规范、口径一致的统计指标,为上层提供公共指标,建立汇总宽表、明细事实表。
应用数据层(ApplicationDataStore, ADS)
这层有的叫做数据集市层( Data Mart, DM),顾名思义,这里的数据就是给顶层的应用程序消费使用,例如整合汇总成分析某一个主题域的报表数据为各种统计报表提供数据。
版权声明:本文为博主「任霏」原创文章,遵循 CC BY-NC-SA 4.0 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://www.renfei.net/posts/1003446
相关推荐
猜你还喜欢这些内容,不妨试试阅读一下以下内容均由网友提交发布,版权与真实性无法查证,请自行辨别。

- 前后端分离项目接口数据加密的秘钥交换逻辑(RSA、AES)
- OmniGraffle 激活/破解 密钥/密匙/Key/License
- Redis 未授权访问漏洞分析 cleanfda 脚本复现漏洞挖矿
- CleanMyMac X 破解版 [TNT] 4.6.0
- OmniPlan 激活/破解 密钥/密匙/Key/License
- 人大金仓 KingbaseES V8 R3 安装包、驱动包和 License 下载地址
- Parallels Desktop For Mac 16.0.1.48911 破解版 [TNT]
- Parallels Desktop For Mac 15.1.4.47270 破解版 [TNT]
- Sound Control 破解版 2.4.2
- CleanMyMac X 破解版 [TNT] 4.6.5
- 博客完全迁移上阿里云,我所使用的阿里云架构
- 微软确认Windows 10存在bug 部分电脑升级后被冻结
- 大佬们在说的AQS,到底啥是个AQS(AbstractQueuedSynchronizer)同步队列
- 比特币(BTC)钱包客户端区块链数据同步慢,区块链数据离线下载
- Java中说的CAS(compare and swap)是个啥
- 小心免费主题!那些WordPress主题后门,一招拥有管理员权限
- 强烈谴责[wamae.win]恶意反向代理我站并篡改我站网页
- 讨论下Java中的volatile和JMM(Java Memory Model)Java内存模型
- 新版个人网站 NEILREN4J 上线并开源程序源码
- 我站近期遭受到恶意不友好访问攻击公告