大数据ETL技术中的数据抽取方法
2021年01月03日 16:56:49 · 本文共 1,618 字阅读时间约 5分钟 · 6,007 次浏览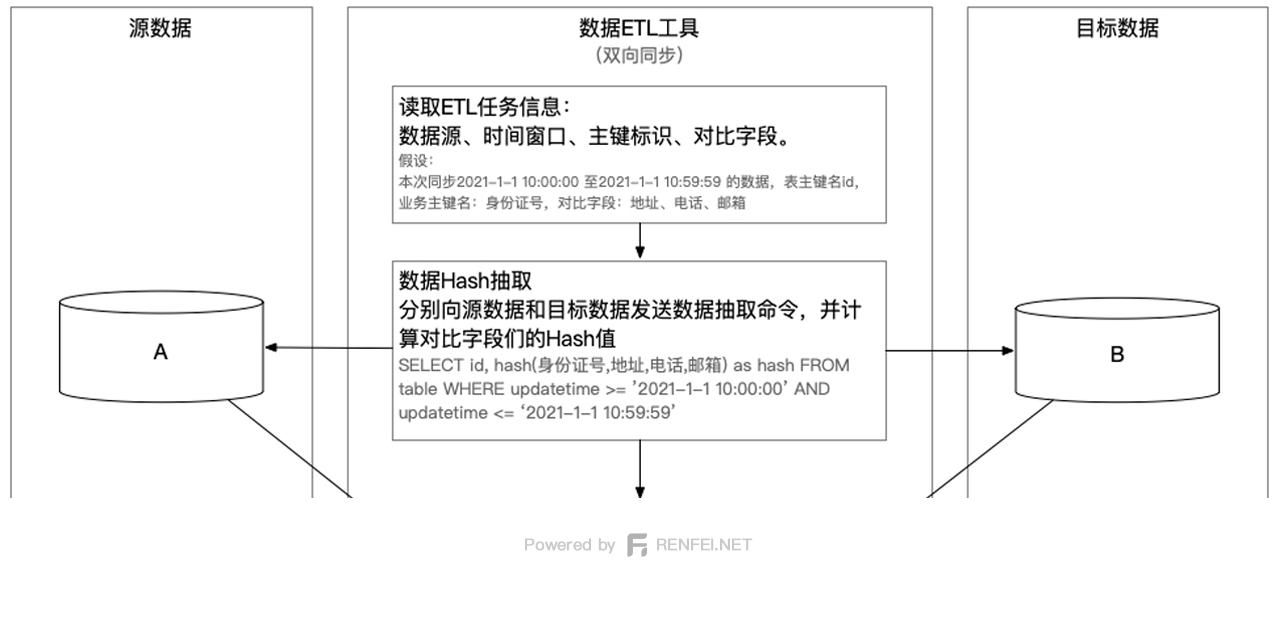
说到大数据仓库技术,不得不提ETL,ETL一词较常用在数据仓库,但其对象并不限于数据仓库。可以说是非常重要的一个环节,简单介绍一下ETL数据抽取比对的方法。
什么是ETL
ETL,是英文Extract-Transform-Load的缩写,用来描述将数据从来源端经过抽取(extract)、转换(transform)、加载(load)至目的端的过程。将业务系统的数据经过抽取、清洗转换之后加载到数据仓库的过程,目的是将企业中的分散、零乱、标准不统一的数据整合到一起,为企业的决策提供分析依据。
全量抽取
全量抽取就是完整复制,比较简单,没有什么需要说的,大部分情况是增量同步。
增量抽取
增量抽取是指基于上次抽取以后,捕捉数据库中的新增、修改、删除的数据变化。在增量抽取时一般不允许影响业务系统的稳定性,所以不能进行锁表或大规模的数据查询。
触发器方案
在业务系统中建立插入、修改、删除三个触发器,每当数据变化时向临时表中添加数据,这样直接可以取到相应的变化量数据,但缺点是会对数据源系统造成侵入,影响数据源系统的性能。
时间戳方案
基于递增数据比较的增量数据捕获方式,在源表上增加一个时间戳字段,系统中更新修改表数据的时候,同时修改时间戳字段的值,进行数据抽取时,通过比较系统时间与时间戳字段的值来决定抽取哪些数据。这个方案无法对比出被删除的数据,同时也对源系统有入侵性,因为要增加时间戳字段,并且要求数据修改的时候更新时间戳字段。
哈希(Hash)对比方案
这个方案是我接下来要重点说的,先看我画的一张图,然后慢慢解释各个节点都是怎么做的:
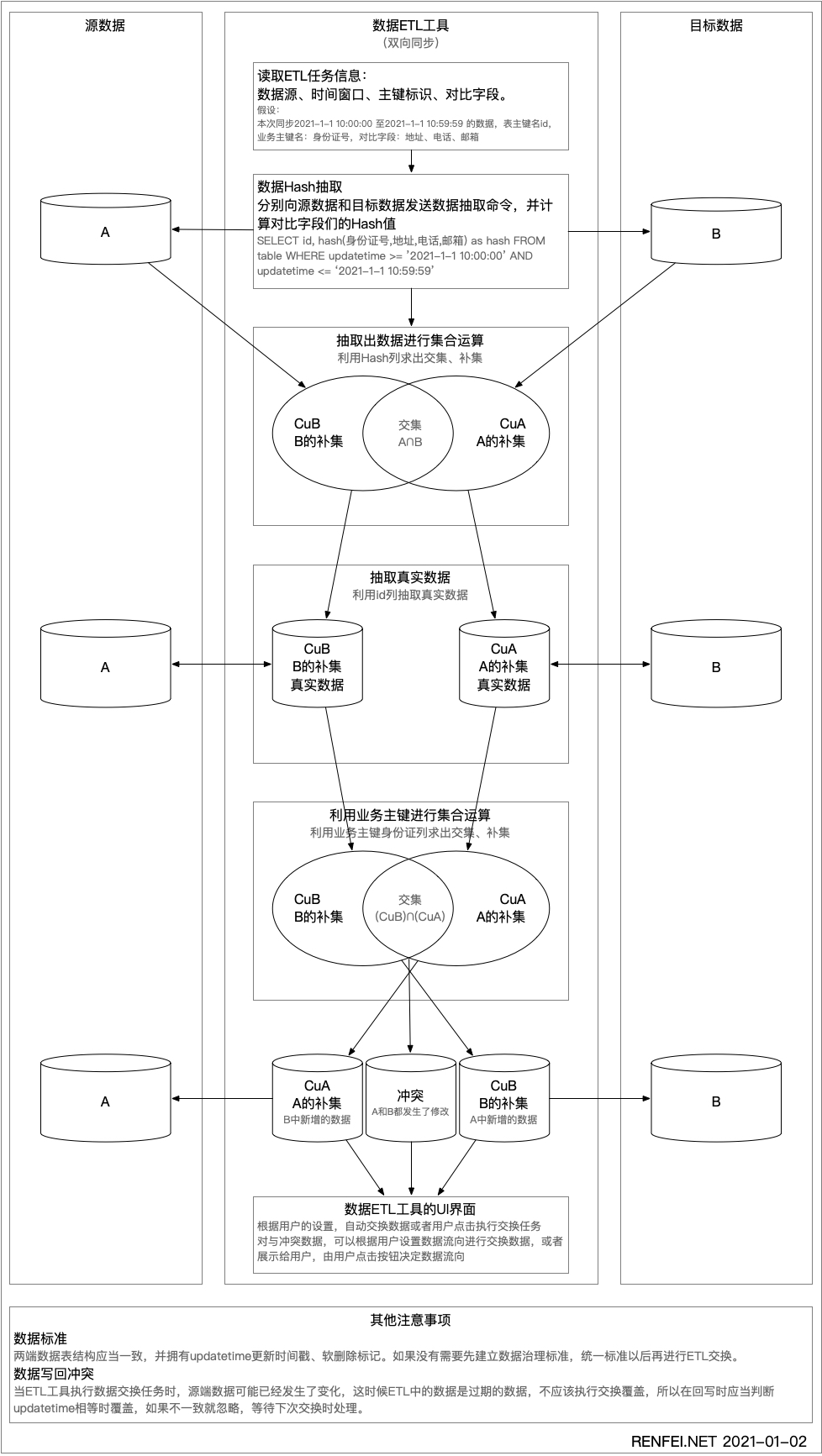
首先获取要对比的时间窗口、对比的字段,注意一定要在同一的一个数据窗口范围内对比,否则是没有意义的,比较常见的是在时间维度上做统一的对比窗口,比如对比一天之内的数据。
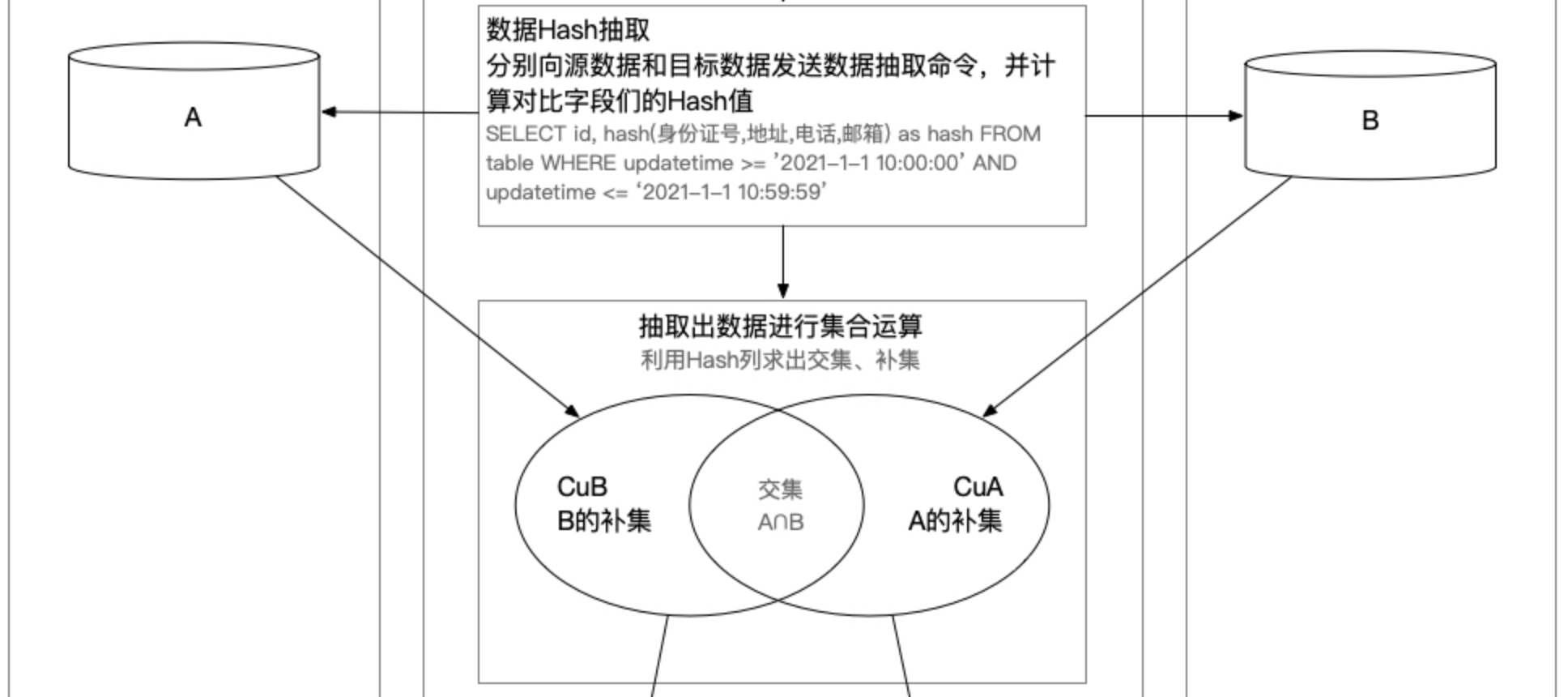
然后分别向源数据端和目标端数据库发送一个SQL,取出主键(例如id)和对比字段们的Hash值,我们就可以得到在一个统一数据窗口内的双方主键和对比列的Hash伪列。

将得到的两个集合求各自的补集,CuB就是B的补集,CuA就是A的补集,也得出了双方的变化量,交集是没有发生变化的数据,可以丢弃了。
计算得到双方的补集CuB和CuA以后,再使用主键去各自的数据源拉取真实的数据过来,注意下面的对比操作都是真实数据,而不是Hash伪列了。
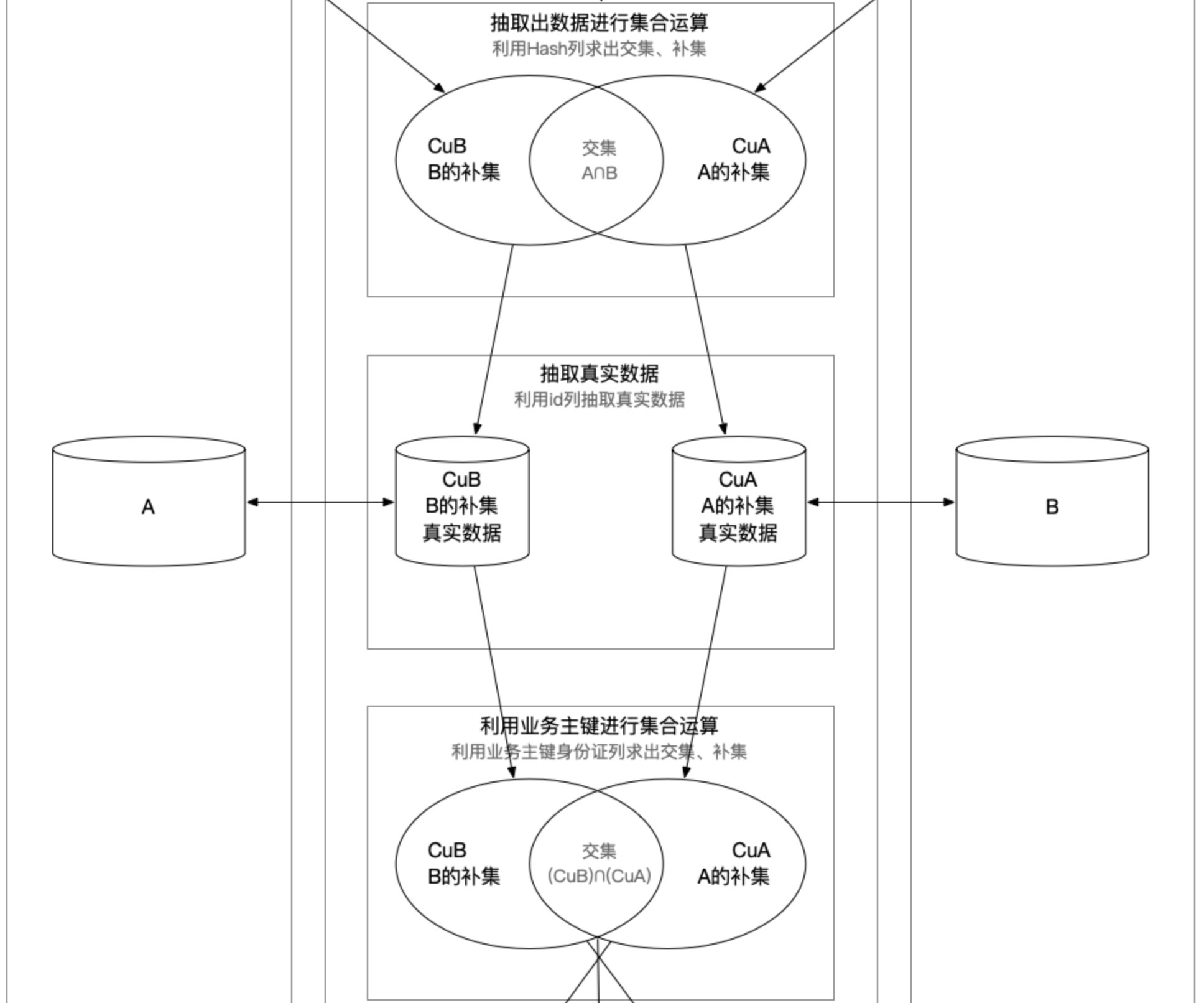
利用业务维度中的主键,再求两个集合的补集和交集,注意这里使用的是业务维度中的唯一主键了(例如身份证号),不是上一步的数据库主键id了,一定要注意。这次求出的CuB就是B的补集,将来要在数据源B中新增的数据,CuA就是将来交给A新增的数据,还有个交集,这个交集就是冲突数据,说明两端数据不一致,需要根据用户设置或者交给用户决定,以哪一侧数据为准进行数据覆盖。
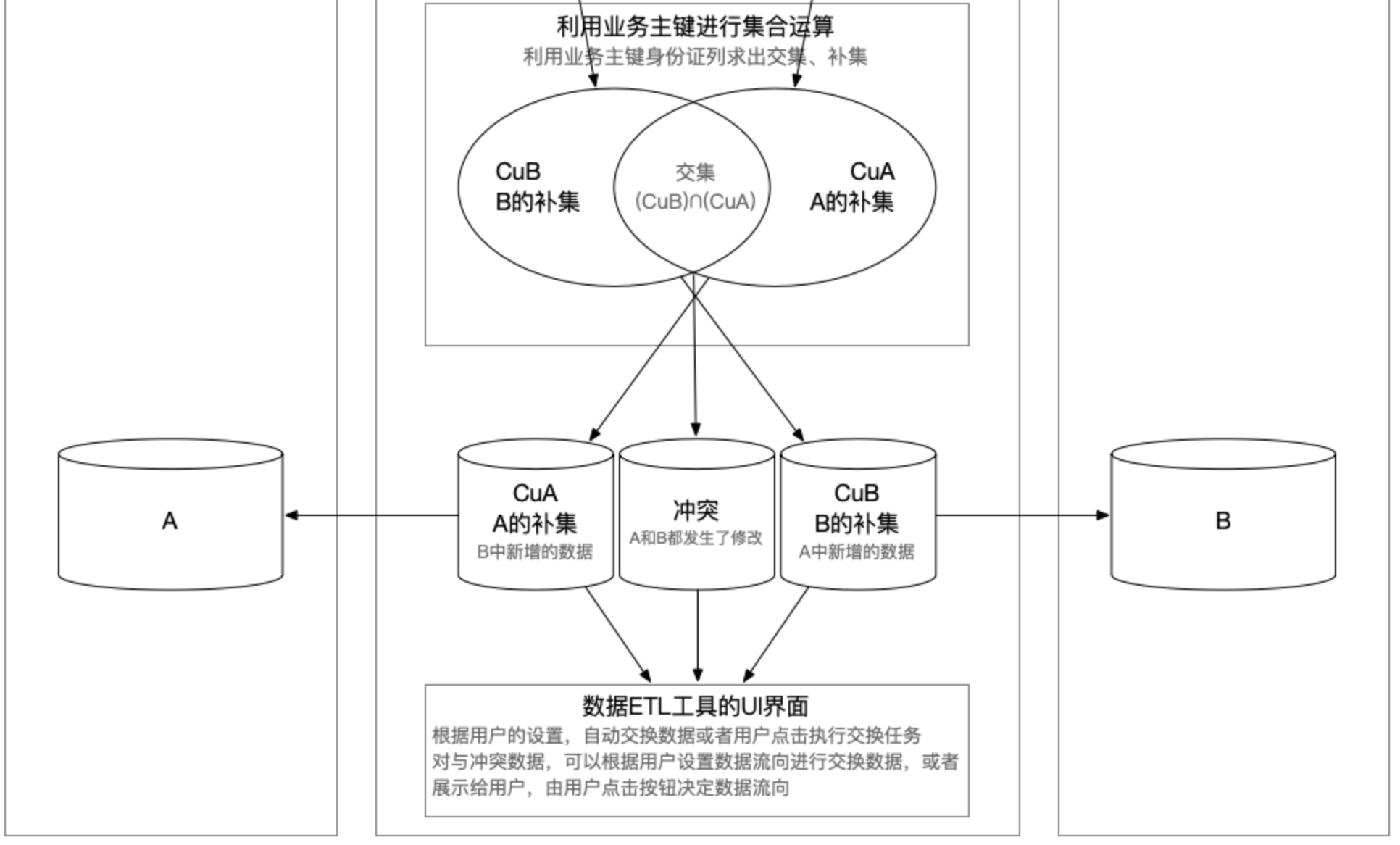
那删除的数据怎么识别出来呢,其实在部署ETL工具之前,就需要先建立数据标准规范,也就是数据治理,里面就规定必须要有删除标记,更新标记。
日志方案
通过分析数据库自身的日志来判断变化的数据。Oracle的改变数据捕获(CDC,Changed Data Capture)技术是这方面的代表。CDC 特性是在Oracle9i数据库中引入的,能够帮助你识别从上次抽取之后发生变化的数据。利用CDC,在对源表进行insert、update或 delete等操作的同时就可以提取数据,并且变化的数据被保存在数据库的变化表中。这样就可以捕获发生变化的数据,然后利用数据库视图以一种可控的方式提供给目标系统。
没有数据治理的情况
在上面的三个方案中,我们都会要求数据源做相应的修改,比如增加触发器、增加时间戳、增加删除字段,但往往在现实中,很多数据源不允许我们修改他们的数据结构,或者不能配合我们做适配。
这种情况下,我们想要识别出数据的增删改,就需要在我们ETL工具内部建立一个镜像机制,也就是给数据源一个快照,然后对比上一次的快照,找出增删改的数据,这种方式虽然入侵性几乎为零,但带来的牺牲就是执行效率上的下降,毕竟需要大量数据的迁移,会影响原有系统的稳定性,而且也需要保存和管理镜像快照。实在没有办法的情况下只能牺牲效率使用这种方案。
设计图下载:ETL.pdf
版权声明:本文为博主「任霏」原创文章,遵循 CC BY-NC-SA 4.0 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://www.renfei.net/posts/1003431
相关推荐
猜你还喜欢这些内容,不妨试试阅读一下
- 前后端分离项目接口数据加密的秘钥交换逻辑(RSA、AES)
- OmniGraffle 激活/破解 密钥/密匙/Key/License
- Redis 未授权访问漏洞分析 cleanfda 脚本复现漏洞挖矿
- CleanMyMac X 破解版 [TNT] 4.6.0
- OmniPlan 激活/破解 密钥/密匙/Key/License
- 人大金仓 KingbaseES V8 R3 安装包、驱动包和 License 下载地址
- Parallels Desktop For Mac 16.0.1.48911 破解版 [TNT]
- Parallels Desktop For Mac 15.1.4.47270 破解版 [TNT]
- Sound Control 破解版 2.4.2
- CleanMyMac X 破解版 [TNT] 4.6.5
- 博客完全迁移上阿里云,我所使用的阿里云架构
- 微软确认Windows 10存在bug 部分电脑升级后被冻结
- 大佬们在说的AQS,到底啥是个AQS(AbstractQueuedSynchronizer)同步队列
- 比特币(BTC)钱包客户端区块链数据同步慢,区块链数据离线下载
- Java中说的CAS(compare and swap)是个啥
- 小心免费主题!那些WordPress主题后门,一招拥有管理员权限
- 强烈谴责[wamae.win]恶意反向代理我站并篡改我站网页
- 讨论下Java中的volatile和JMM(Java Memory Model)Java内存模型
- 新版个人网站 NEILREN4J 上线并开源程序源码
- 我站近期遭受到恶意不友好访问攻击公告