Hadoop入门教程(三):Hadoop 单节点本地运行与伪分布式
2021年03月09日 11:00:16 · 本文共 2,830 字阅读时间约 10分钟 · 2,979 次浏览
因为是入门学习,很多同学的电脑性能不具备集群环境的要求,我们先了解一下 Hadoop 单节点运行模式,以便您可以使用 Hadoop MapReduce和 Hadoop 分布式文件系统(HDFS)快速执行简单的操作。本节内容主要是带新手体验一下 Hadoop 的案例,相当于 Hello World 案例,揭开 Hadoop 神秘的面纱。
先决条件
本教程的内容都来自 Apache Hadoop 的官方文档:https://hadoop.apache.org/docs/r2.10.1/hadoop-project-dist/hadoop-common/SingleCluster.html,如果您需要阅读原文,可以去看看。
上一篇讲了 Hadoop 的安装教程,如果还没安装,请先安装 Hadoop 再尝试本篇教程。
配置 Hadoop 启动脚本
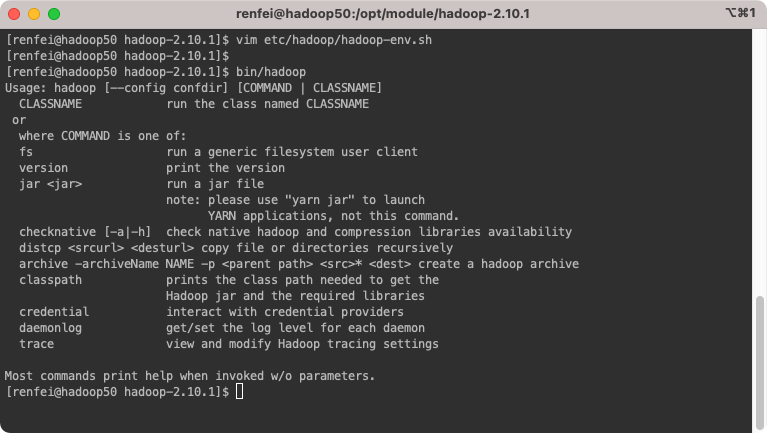
我们需要先编辑 etc/hadoop/hadoop-env.sh 脚本,上一篇教程将 Hadoop 安装到了 /opt/module/hadoop-2.10.1,所以配置文件位置就在 /opt/module/hadoop-2.10.1/etc/hadoop/hadoop-env.sh。
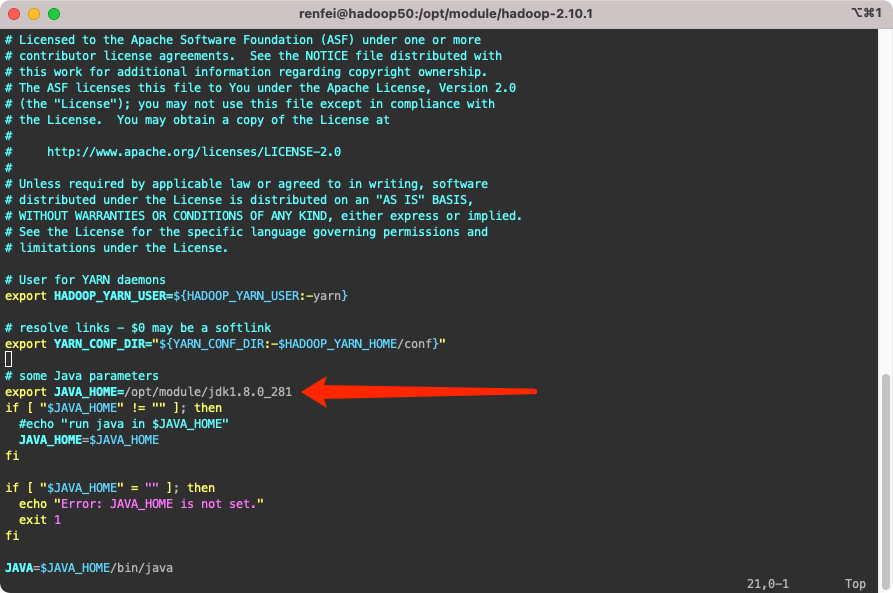
根据官方文档的要求,我们需要配置这个脚本中的 export JAVA_HOME=/usr/java/latest,上一篇教程将 JDK 安装到了 /opt/module/jdk1.8.0_281,所以我这里修改的内容就是:
export JAVA_HOME=/opt/module/jdk1.8.0_281配置完成后执行 /opt/module/hadoop-2.10.1/bin/hadoop 进行测试,这将显示hadoop脚本的用法文档。
单节点运行配置
默认情况下,Hadoop被配置为以非分布式模式(non-distributed mode)作为单个Java进程运行,调试的时候才会使用。如上所说,本地模式在调试的时候会使用,不会在生产环境中使用。
安装官方文档的内容,我们验证以下,执行以下命令:
mkdir input
cp etc/hadoop/*.xml input
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.10.1.jar grep input output 'dfs[a-z.]+'
cat output/*这其实就是类似 Hello World,就是将conf目录作为输入,然后查找并显示给定正则表达式的每个匹配项。输出被写入给定的输出目录。这就使用 Hadoop 执行了一次查询。
再体验一下官方WordCount案例
官方还为我们准备了一个体验案例 WordCount,就是统计单词数量,我们可以这样体验:
新建一个文件夹 wcinput,再在里面新建 wc.input 文件,写入一些文本,让 Hadoop 帮我们统计单词数量。
mkdir wcinput
touch wcinput/wc.input
vim wcinputu/wc.input#写入我们的文本,如以下内容(去掉井号):
#hadoop test
#hadoop renfei
#renfei yarn
# 执行 wordcount 案例,输入文件夹是 wcinput,输出文件夹是 wcoutput
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.10.1.jar wordcount wcinput wcoutput
# 查看结果
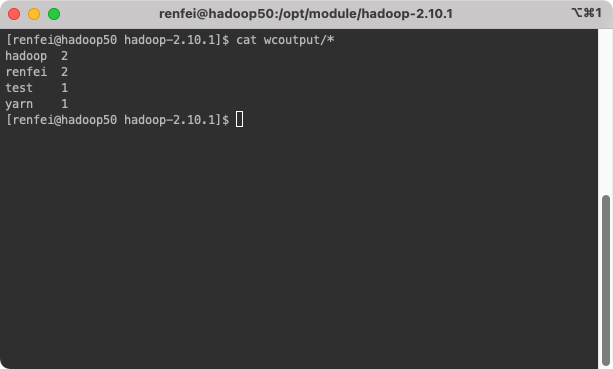
cat wcoutput/*到这里,你又一次体验了 Hadoop 的强大,他帮我们统计出了单词的数量。
伪分布式模式
根据官方文档说明:Hadoop也可以以伪分布式模式在单节点上运行,其中每个Hadoop守护程序都在单独的Java进程中运行。我们需要修改 etc/hadoop/core-site.xml、etc/hadoop/hdfs-site.xml,我就按照我的环境配置了,配置如下:
etc/hadoop/core-site.xml:
<configuration>
<!-- 指定HDFS中NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
<!-- 指定Hadoop运行时产生的文件存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-2.10.1/data/tmp</value>
</property>
</configuration>etc/hadoop/hdfs-site.xml:
<configuration>
<!-- 指定HDFS副本数量 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>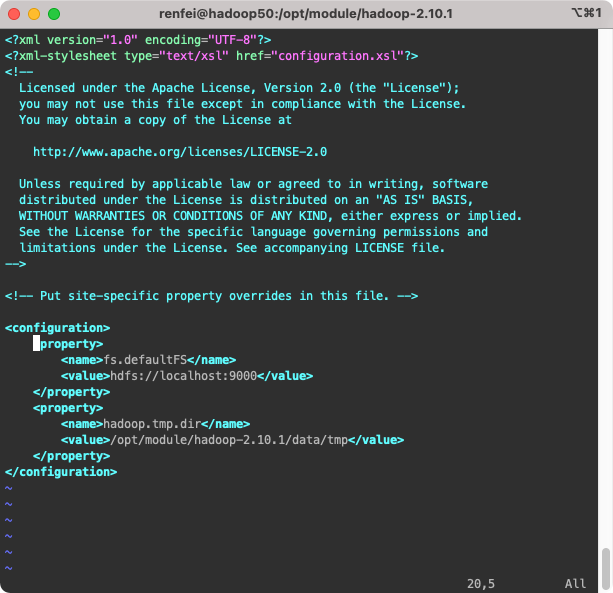
格式化文件系统
首次启动时格式化文件系统,只有首次需要格式化,重复格式化会出现问题:
bin/hdfs namenode -format启动NameNode守护程序和DataNode守护程序
sbin/start-dfs.sh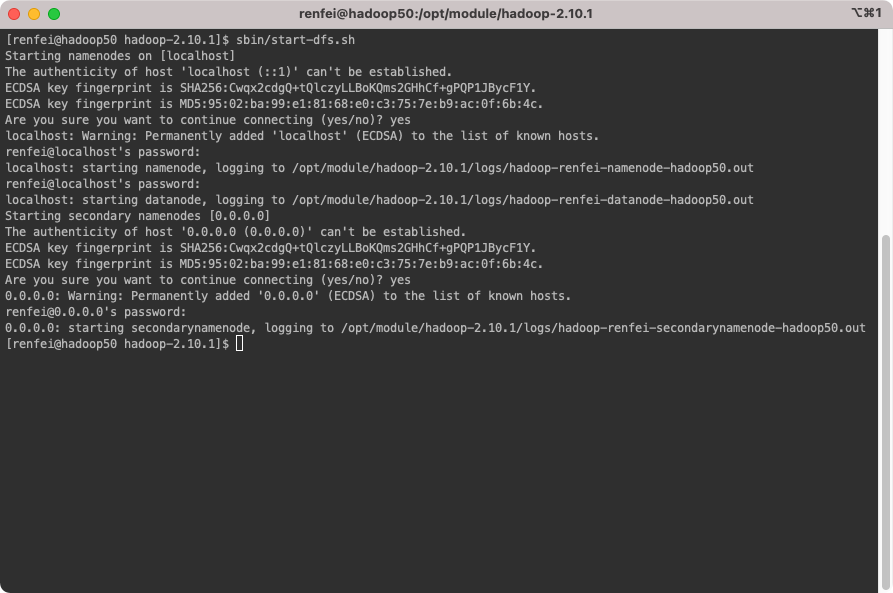
浏览Web界面以查找NameNode
我这里的IP是 192.168.1.50,你需要换成你的 Hadoop IP 地址,来访问50070端口:http://192.168.1.50:50070,看到如下画面:
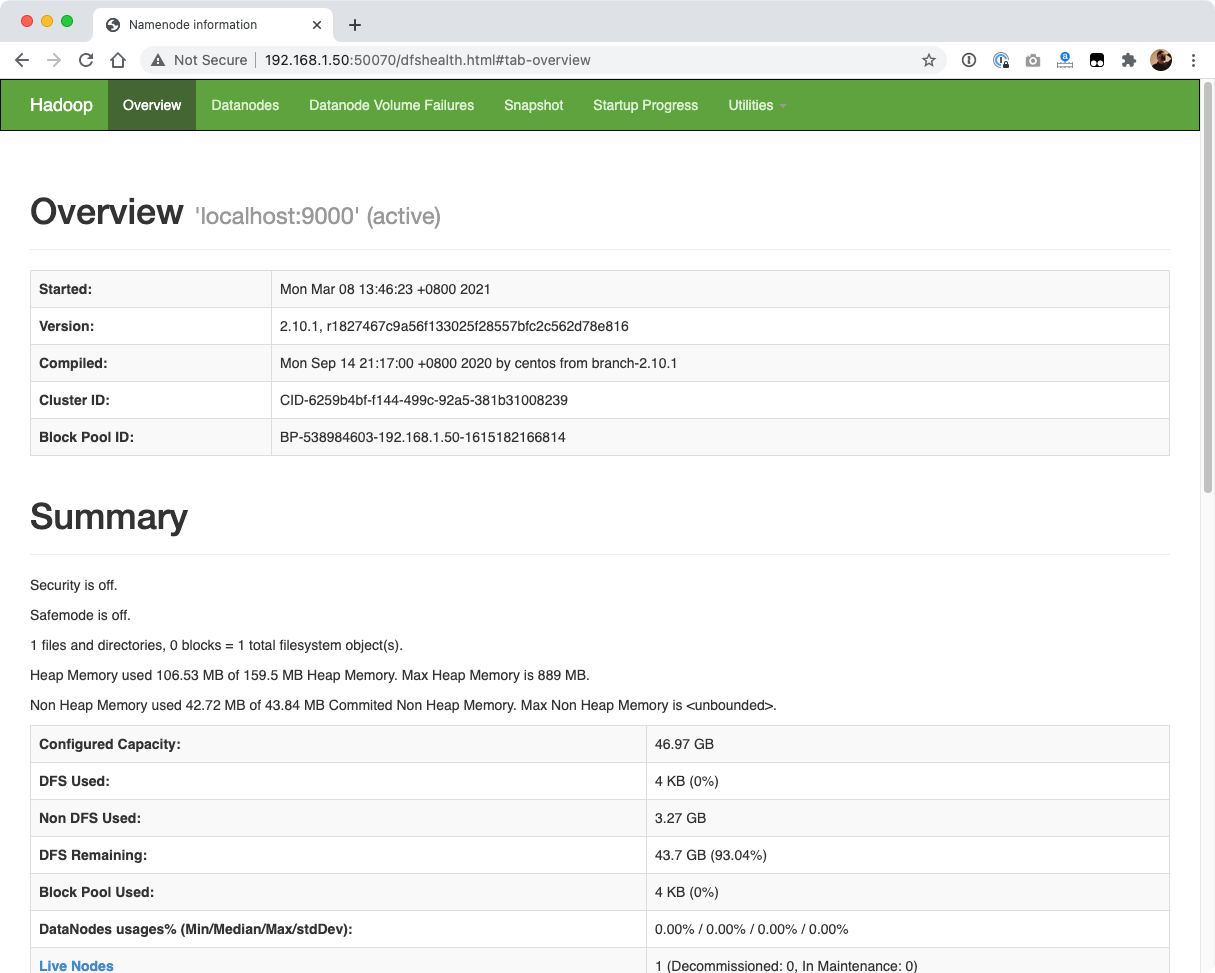
Yarn的伪分布式模式
编辑 etc/hadoop/yarn-env.sh、etc/hadoop/mapred-env.sh,配置 JAVA_HOME,这里就不赘述了。
配置 etc/hadoop/yarn-site.xml:
<configuration>
<!-- Reducer 获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定YARN的ResourceManager地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop50</value>
</property>
</configuration>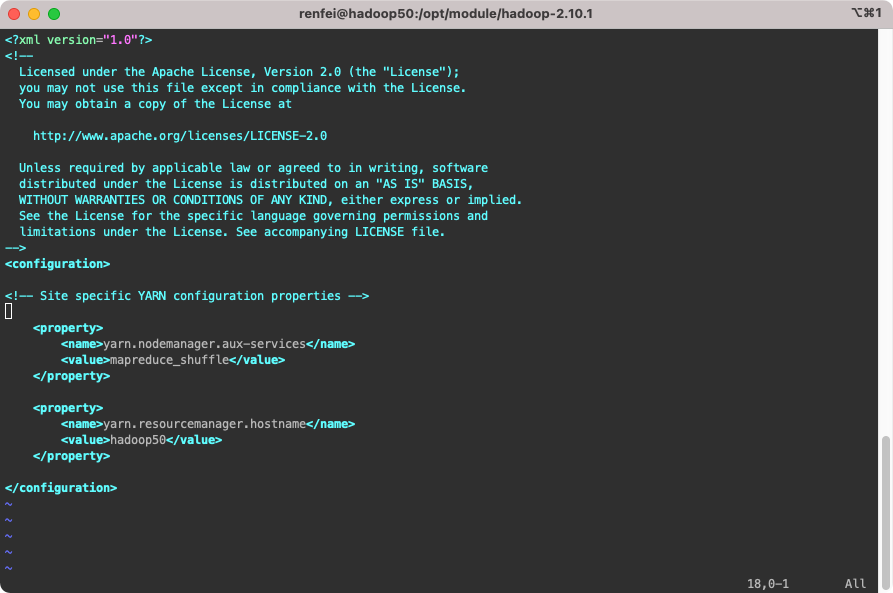
重命名 etc/hadoop/mapred-site.xml.template 为 etc/hadoop/mapred-site.xml,并修改配置:
<configuration>
<!-- 指定 MR 运行在 YARN 上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>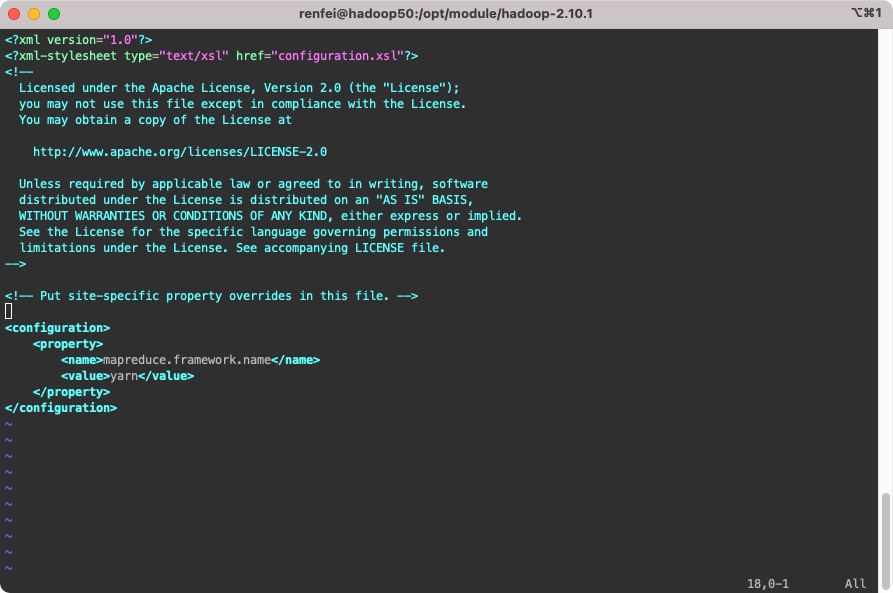
启动集群
首先保证 NameNode 和 DataNode 已经启动,然后启动 ResourceManager 和 NodeManager:
sbin/start-yarn.sh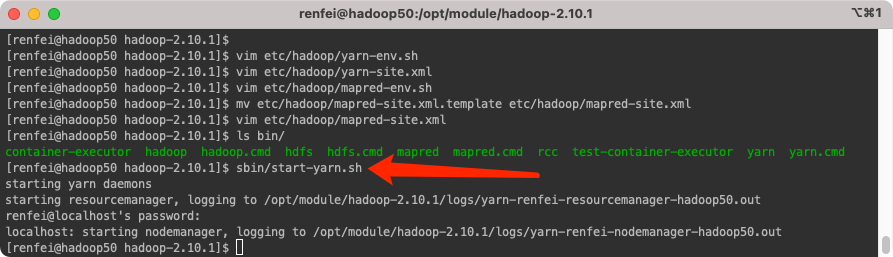
然后使用浏览器访问,我这里的IP是 192.168.1.50,你需要换成你的 Hadoop IP 地址,来访问8088端口:http://192.168.1.50:8088/cluster,看到如下画面:
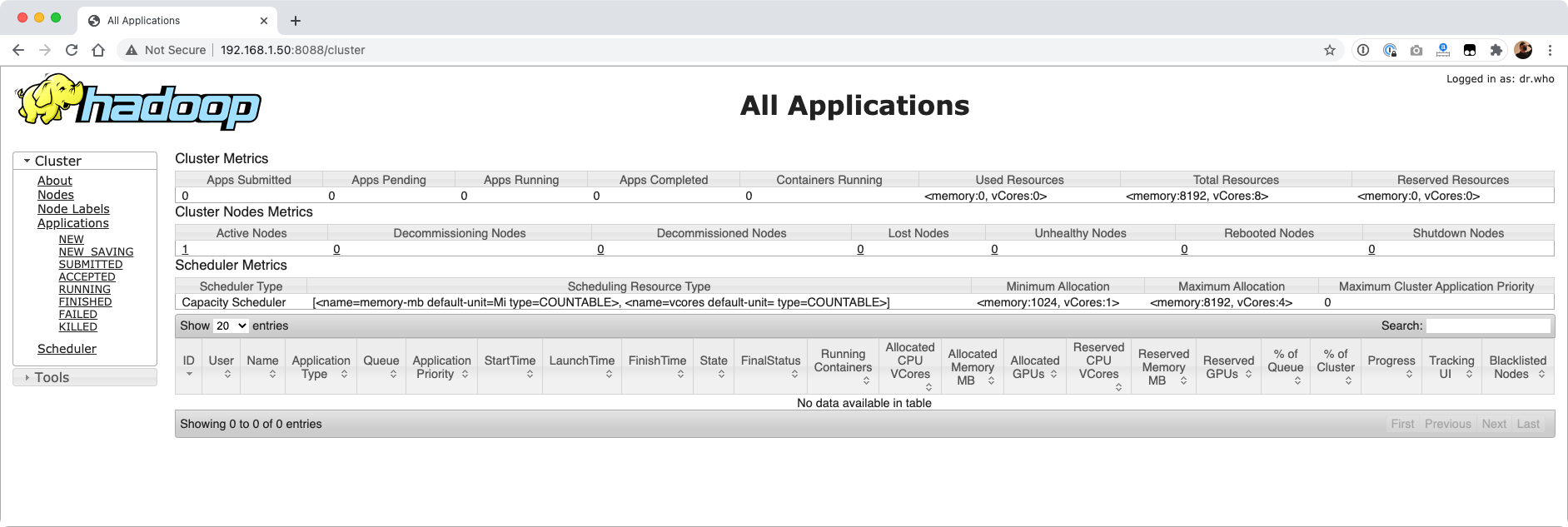
体验伪分布式模式的 Hadoop
体验伪分布式模式的 Hadoop时,需要将我们的本地文件上传到 HDFS 上,使用如下命令:
hadoop fs -put wcinput /在 http://192.168.1.50:50070/explorer.html 中我们可以看到上传成功的文件:
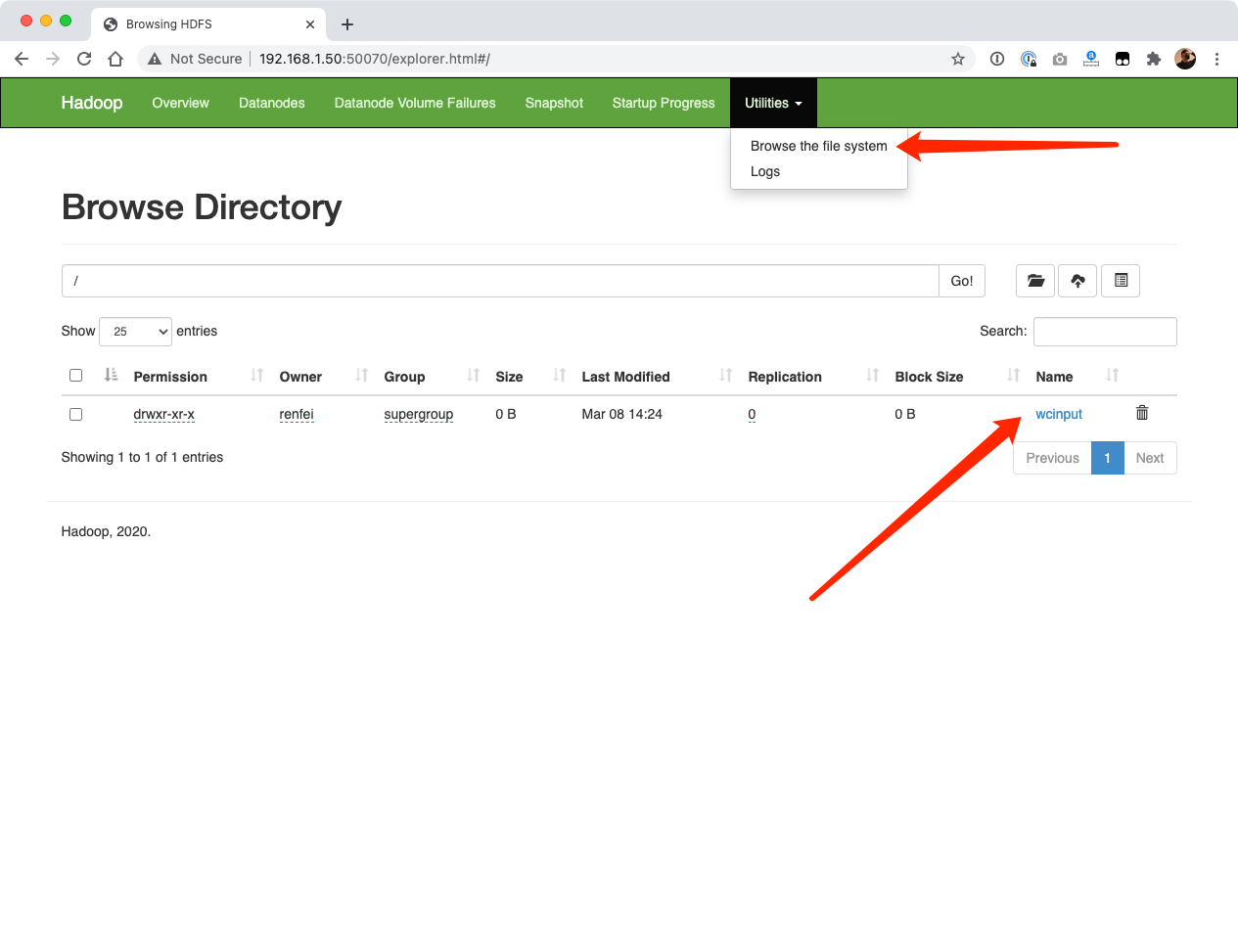
再次执行WordCount案例,不过这次输入文件夹,注意前面是个杠 /,是走的 HDFS 的根目录,而不是本地的:
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.10.1.jar wordcount /wcinput /wcoutput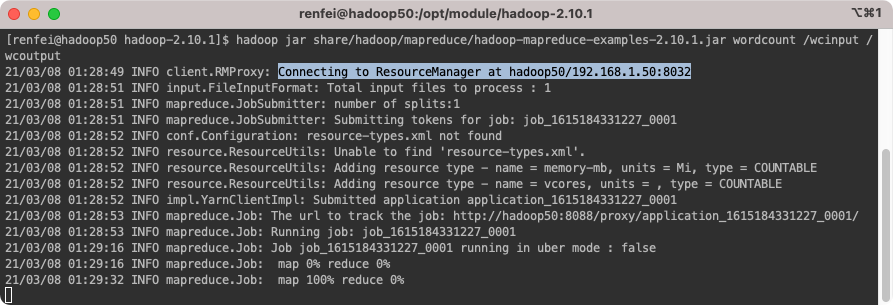
执行成功以后我们可以在浏览器中看到已经有 wcoutput 输出文件夹了,我们使用 HDFS 看看内容:
hadoop fs -cat /wcoutput/*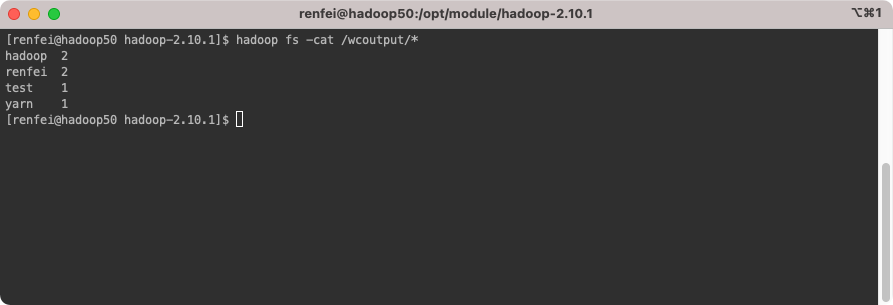
完全分布式
在现实生产环境中,我们不可能使用单节点运行,所以重点还是分布式的 Hadoop,下一节将带大家搭建完全分布式的集群 Hadoop。
版权声明:本文为博主「任霏」原创文章,遵循 CC BY-NC-SA 4.0 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://www.renfei.net/posts/1003459
相关推荐
猜你还喜欢这些内容,不妨试试阅读一下以下内容均由网友提交发布,版权与真实性无法查证,请自行辨别。

- 前后端分离项目接口数据加密的秘钥交换逻辑(RSA、AES)
- OmniGraffle 激活/破解 密钥/密匙/Key/License
- CleanMyMac X 破解版 [TNT] 4.6.0
- OmniPlan 激活/破解 密钥/密匙/Key/License
- 人大金仓 KingbaseES V8 R3 安装包、驱动包和 License 下载地址
- Parallels Desktop For Mac 16.0.1.48911 破解版 [TNT]
- Redis 未授权访问漏洞分析 cleanfda 脚本复现漏洞挖矿
- Parallels Desktop For Mac 15.1.4.47270 破解版 [TNT]
- Sound Control 破解版 2.4.2
- 向谷歌搜索引擎主动推送网页的教程 Google Indexing API 接口实现
- 博客完全迁移上阿里云,我所使用的阿里云架构
- 微软确认Windows 10存在bug 部分电脑升级后被冻结
- 大佬们在说的AQS,到底啥是个AQS(AbstractQueuedSynchronizer)同步队列
- 比特币(BTC)钱包客户端区块链数据同步慢,区块链数据离线下载
- Java中说的CAS(compare and swap)是个啥
- 小心免费主题!那些WordPress主题后门,一招拥有管理员权限
- 强烈谴责[wamae.win]恶意反向代理我站并篡改我站网页
- 讨论下Java中的volatile和JMM(Java Memory Model)Java内存模型
- 新版个人网站 NEILREN4J 上线并开源程序源码
- 我站近期遭受到恶意不友好访问攻击公告