Hadoop入门教程(二):Hadoop 的安装教程
2021年03月08日 12:38:09 · 本文共 1,914 字阅读时间约 6分钟 · 2,930 次浏览
在开始我们的 Hadoop 之旅前,我们需要先学会安装 Hadoop ,在后面我们将使用多个 Hadoop 节点进行试验和学习,本文将带你安装 Hadoop,这是非常简单的。
本教程所需基础内容
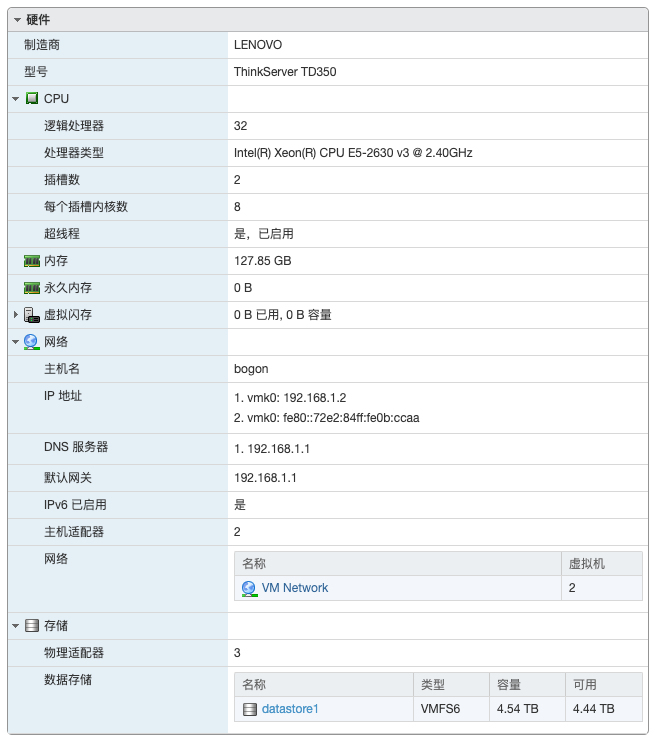
在开始本教程前,您应当具备 Linux 的基本操作知识,并安装准备好一台 Linux 操作系统的主机,本文将使用 CentOS7 进行演示,其中包括普通账号添加、 JDK 的安装、 Hadoop 的安装、环境变量配置。在后面我们将使用多个 Hadoop 主机节点进行试验和学习,我是在服务器上安装虚拟机进行试验和学习的,物理服务器配置为两颗 Xeon E5-2630 v3 CPU、128G内存,如果您在自己的电脑上进行搭建,学习大数据需要最低 16G 的运行内存,否则可能无法运行起所有大数据组件。
修改网络IP、主机名和Hosts文件
为了在以后搭建 Hadoop 集群,我们需要让每个机器的 IP 地址固定下来,并相互知道各自的 IP 地址,所以就需要修改网络 IP 为静态地址,并且修改主机名、hosts 文件让各个 Hadoop 节点可以解析到其他节点的 IP 地址。
我们先使用 ls /etc/sysconfig/network-scripts/ 查看网卡名称,我这里叫 ifcfg-ens192,然后使用 vi 编辑它的配置:

我们需要修改 BOOTPROTO=static、ONBOOT=yes,并在结尾添加下面的配置,请根据自己的网络环境修改:
IPADDR=192.168.1.50
NETMASK=255.255.255.0
GATEWAY=192.168.1.1
DNS1=192.168.1.1
DNS2=114.114.114.114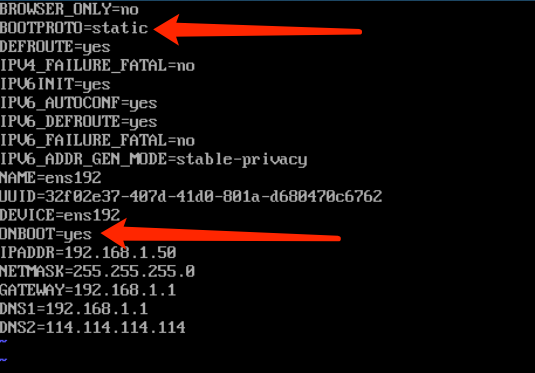
重启网卡使配置生效:
systemctl restart network修改主机名
hostnamectl set-hostname hadoop50修改 hosts 文件,我这里设置10个节点作为 Hadoop 集群
vi /etc/hosts #写入:
192.168.1.50 hadoop50
192.168.1.51 hadoop51
192.168.1.52 hadoop52
192.168.1.53 hadoop53
192.168.1.54 hadoop54
192.168.1.55 hadoop55
192.168.1.56 hadoop56
192.168.1.57 hadoop57
192.168.1.58 hadoop58
192.168.1.59 hadoop59关闭防火墙
关闭防火墙是为了让集群内部之间更方便的通信,关闭的前提是在集群外部有其他的防火墙进行安全拦截,如果生产环境中外部没有其他防火墙那么本地的防火墙就需要打开,需要配置每个用到的端口,由于这是入门教程,我们直接关闭防火墙,省去因网络不通而产生莫名其妙的故障。
systemctl stop firewalld.service #停止firewall
systemctl disable firewalld.service #禁止firewall开机启动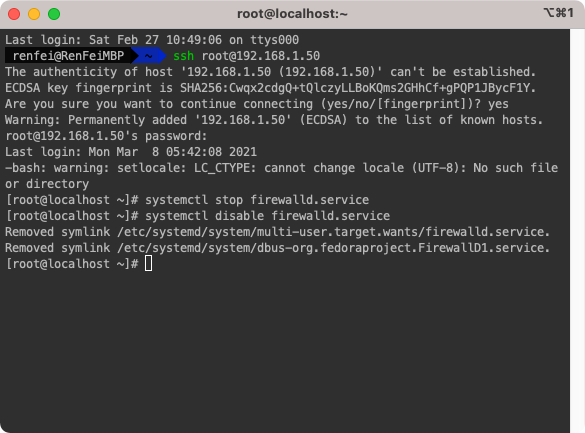
添加普通用户
在任何 Linux 使用场景下,我们都不建议直接使用 root 账号进行操作,以最高权限 root 运行的程序权限过大很不安全,所以我们都应该使用普通账号登陆进来使用。
useradd renfei#添加普通用户
passwd renfei#设置新添加用户的密码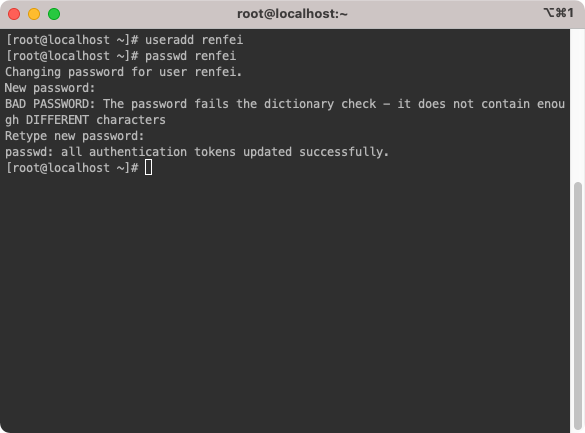
给予普通用户使用 sudo 的权限
编辑 /etc/sudoers,添加如下内容:
renfei ALL=(ALL) ALL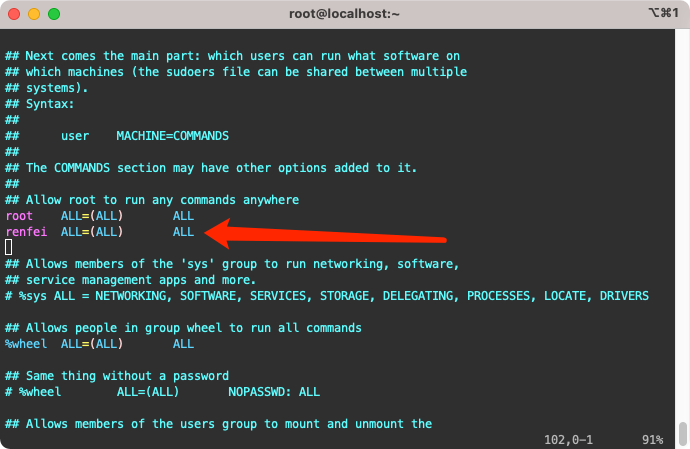
创建安装目录和存储目录
为了清楚的知道我们软件在哪里,我们统一创建两个文件夹:/opt/software、/opt/module,其中 /opt/software 存放我们的软件安装包,/opt/module 是软件安装目录。创建以后给予我们新建的普通用户权限。
mkdir /opt/module /opt/software
chown renfei:renfei /opt/module /opt/software安装JDK和Hadoop
切换到普通用户,然后开始安装JDK和Hadoop。
安装JDK
下载好JDK,放到 /opt/software,解压到 /opt/module,然后配置 JAVA_HOME 环境变量:
tar -zxvf /opt/software/jdk-8u281-linux-x64.tar.gz -C /opt/module/#解压 JDK 到 /opt/module/
sudo vi /etc/profile#编辑环境变量,添加以下内容,注意去掉前面的井号(#),这里是为了展示内容:
#export JAVA_HOME=/opt/module/jdk1.8.0_281
#export PATH=$PATH:$JAVA_HOME/bin
source /etc/profile#让环境变量生效
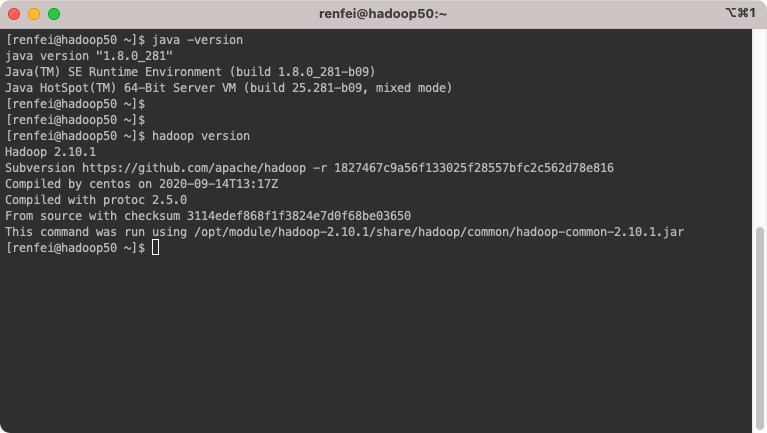
java -version#验证 JDK 安装正确安装Hadoop
跟安装 JDK 一样,我们需要先解压,然后配置 HADOOP_HOME 环境变量:
tar -zxvf /opt/software/hadoop-2.10.1.tar.gz -C /opt/module/#解压 Hadoop 到 /opt/module/hadoop-2.10.1
sudo vi /etc/profile#编辑环境变量,添加以下内容,注意去掉前面的井号(#),包含了上面的JDK内容,这里是为了展示内容:
#export JAVA_HOME=/opt/module/jdk1.8.0_281
#export HADOOP_HOME=/opt/module/hadoop-2.10.1
#export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
source /etc/profile#让环境变量生效
hadoop version#验证 Hadoop 安装正确至此,您已经将 Hadoop 安装完成了,后续我们将开始使用它。
版权声明:本文为博主「任霏」原创文章,遵循 CC BY-NC-SA 4.0 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://www.renfei.net/posts/1003458
相关推荐
猜你还喜欢这些内容,不妨试试阅读一下以下内容均由网友提交发布,版权与真实性无法查证,请自行辨别。

- 前后端分离项目接口数据加密的秘钥交换逻辑(RSA、AES)
- OmniGraffle 激活/破解 密钥/密匙/Key/License
- CleanMyMac X 破解版 [TNT] 4.6.0
- OmniPlan 激活/破解 密钥/密匙/Key/License
- 人大金仓 KingbaseES V8 R3 安装包、驱动包和 License 下载地址
- Parallels Desktop For Mac 16.0.1.48911 破解版 [TNT]
- Redis 未授权访问漏洞分析 cleanfda 脚本复现漏洞挖矿
- Parallels Desktop For Mac 15.1.4.47270 破解版 [TNT]
- Sound Control 破解版 2.4.2
- 向谷歌搜索引擎主动推送网页的教程 Google Indexing API 接口实现
- 博客完全迁移上阿里云,我所使用的阿里云架构
- 微软确认Windows 10存在bug 部分电脑升级后被冻结
- 大佬们在说的AQS,到底啥是个AQS(AbstractQueuedSynchronizer)同步队列
- 比特币(BTC)钱包客户端区块链数据同步慢,区块链数据离线下载
- Java中说的CAS(compare and swap)是个啥
- 小心免费主题!那些WordPress主题后门,一招拥有管理员权限
- 强烈谴责[wamae.win]恶意反向代理我站并篡改我站网页
- 讨论下Java中的volatile和JMM(Java Memory Model)Java内存模型
- 新版个人网站 NEILREN4J 上线并开源程序源码
- 我站近期遭受到恶意不友好访问攻击公告