Hadoop入门教程(七):HDFS 数据读写流程
2021年03月17日 10:33:28 · 本文共 969 字阅读时间约 3分钟 · 3,064 次浏览
教程索引目录请访问:《大数据技术入门级系列教程》
上一篇我们已经可以通过编程的方式操作 HDFS 了,但这一切背后在Hadoop集群里发生了什么呢,本篇文章简单介绍一下 HDFS 的读写流程。
数据写入流程
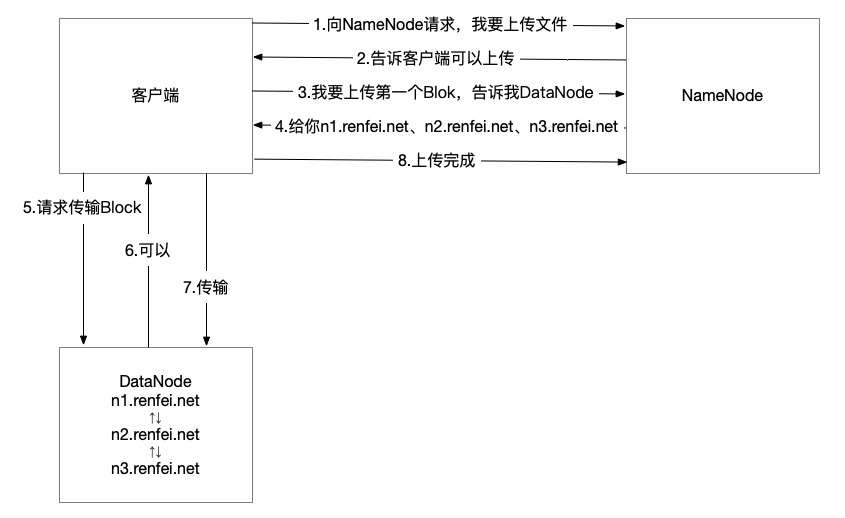
- 客户端向 NameNode 请求上传文件,NameNode 检查目标文件是否已存在,父目录是否存在。
- NameNode 返回是否可以上传。
- 客户端请求第一个 Block 上传到哪几个 DataNode 服务器上。
- NameNode 返回3个 DataNode 节点,分别为n1、n2、n3。
- 客户端请求n1上传数据,n1收到请求会继续调用n2,然后n2调用n3,将这个通信管道建立完成。
- n1、n2、n3逐级应答客户端。
- 客户端开始往n1上传第一个Block(先从磁盘读取数据放到一个本地内存缓存),以 Packet 为单位,n1收到一个 Packet 就会传给n2,n2传给dn3;n1每传一个 packet 会放入一个应答队列等待应答。
- 当一个 Block 传输完成之后,客户端再次请求 NameNode 上传第二个Block的服务器。(重复执行3-7步)。
数据读取流程
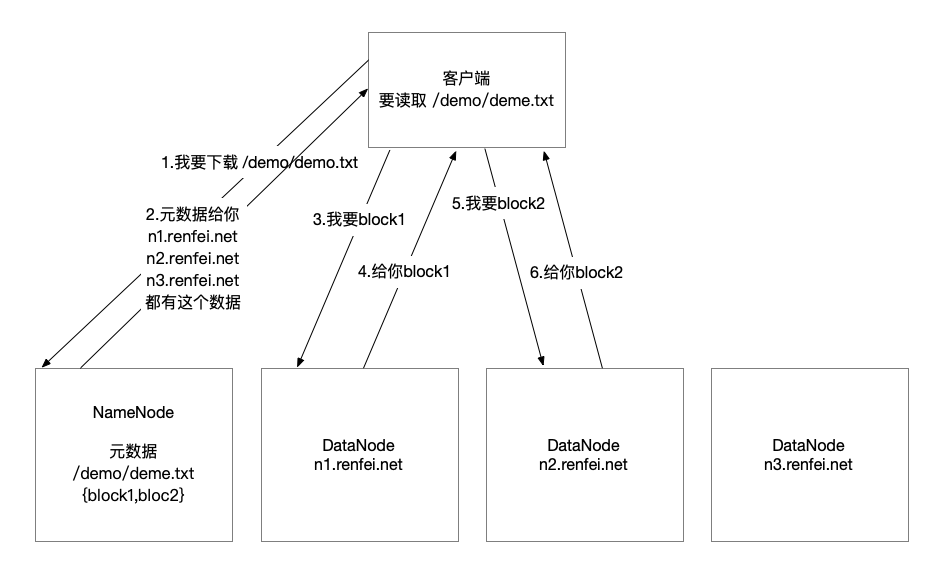
- 客户端向 NameNode 请求下载文件,NameNode 通过查询元数据,找到文件块所在的 DataNode 地址。
- 挑选一台 DataNode(就近原则,然后随机)服务器,请求读取数据。
- DataNode 开始传输数据给客户端(从磁盘里面读取数据输入流,以 Packet 为单位来做校验)。
- 客户端以 Packet 为单位接收,先在本地缓存,然后写入目标文件。
机架感知
我们为了数据安全,尽量会分散开数据,所以会跨机架甚至跨可用区进行部署,防止某个机架故障导致全部集群故障,而距离的远近会影响性能,所以 Hadoop 还有机架感知的功能,这里我主要是看官网的文档:https://hadoop.apache.org/docs/r2.10.1/hadoop-project-dist/hadoop-hdfs/HdfsDesign.html#Data_Replication。
其实计算距离只需要看网络数据包跳了几跳就行,如果在同一个机架上,都在同一个交换机上,几乎是直达无需跳转,如果要出去就需要好几个路由跳转,从而就可以判断距离远近了。
官方文档是这样说的,我摘抄一部分:
当复制因子为3时,HDFS的放置策略是:如果写入器在数据节点上,则将一个副本放置在本地计;否则,在随机数据节点上,将HDFS放置在不同(远程)机架中的节点上的另一个副本。 最后一个位于同一远程机架中的其他节点上。该策略减少了机架间的写流量,通常可以提高写性能。机架故障的机会远小于节点故障的机会。此策略不会影响数据的可靠性和可用性保证。
商业用途请联系作者获得授权。
版权声明:本文为博主「任霏」原创文章,遵循 CC BY-NC-SA 4.0 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://www.renfei.net/posts/1003466
版权声明:本文为博主「任霏」原创文章,遵循 CC BY-NC-SA 4.0 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://www.renfei.net/posts/1003466
相关推荐
猜你还喜欢这些内容,不妨试试阅读一下
评论与留言
以下内容均由网友提交发布,版权与真实性无法查证,请自行辨别。

热评文章
- 前后端分离项目接口数据加密的秘钥交换逻辑(RSA、AES)
- OmniGraffle 激活/破解 密钥/密匙/Key/License
- Redis 未授权访问漏洞分析 cleanfda 脚本复现漏洞挖矿
- CleanMyMac X 破解版 [TNT] 4.6.0
- OmniPlan 激活/破解 密钥/密匙/Key/License
- 人大金仓 KingbaseES V8 R3 安装包、驱动包和 License 下载地址
- Parallels Desktop For Mac 16.0.1.48911 破解版 [TNT]
- Parallels Desktop For Mac 15.1.4.47270 破解版 [TNT]
- Sound Control 破解版 2.4.2
- CleanMyMac X 破解版 [TNT] 4.6.5
热文排行
- 博客完全迁移上阿里云,我所使用的阿里云架构
- 微软确认Windows 10存在bug 部分电脑升级后被冻结
- 大佬们在说的AQS,到底啥是个AQS(AbstractQueuedSynchronizer)同步队列
- 比特币(BTC)钱包客户端区块链数据同步慢,区块链数据离线下载
- Java中说的CAS(compare and swap)是个啥
- 小心免费主题!那些WordPress主题后门,一招拥有管理员权限
- 强烈谴责[wamae.win]恶意反向代理我站并篡改我站网页
- 讨论下Java中的volatile和JMM(Java Memory Model)Java内存模型
- 新版个人网站 NEILREN4J 上线并开源程序源码
- 我站近期遭受到恶意不友好访问攻击公告